Read Replicas on Hasura OSS
The most important challenges on production are performance and high availability. Database service is the Single Point of Failure of backend services. Hasura GraphQL Engine isn't different.
High availability can be solved by database replication solutions. Otherwise, performance can be improved by load balancing read requests with read replicas. However, this problem requires the support of application.
As you probably know, Read Replicas feature are exclusively supported on Hasura Pro and Cloud versions. However, you still can setup read replicas on OSS version.
Read-only mode
Recently, Hasura team releases an experiment read-only GraphQL Engine image that can run on read replica server.
Thank for that, the idea becomes simple. We just deploy 2 GraphQL Engine groups:
- Primary: connect to Primary database server.
- Read-only: connect to Read replica servers.
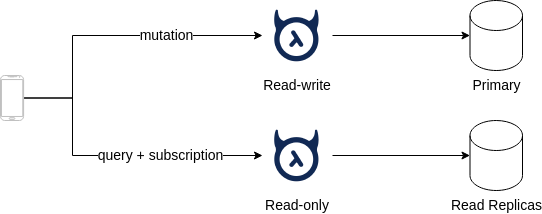
Client applications do routing GraphQL requests to 2 endpoints:
- mutation: requests to primary endpoint.
- query & subscription: requests to read-only endpoint.
Caveat
- Metadata is loaded once on startup. New metadata changes aren't reloaded on read-only instance. Therefore you have to restart the container to refresh metadata.
- Need more works on client applications.
- Most of functions on Hasura console is unusable. However it isn't problem. We can use the primary console instead.
Implementation
You can download and run the demo here
The demo simulates above diagram, using docker-compose:
- app: React webapp demo.
- postgres-master: Postgres master server.
- postgres-replica: Postgres replica server.
- data: GraphQL Engine primary instance that connects to
postgres-master. - data-readonly: Read-only GraphQL Engine instance that connects to
postgres-replica.
*Note: Metadata on read-only instance can't be reloaded. So you have to restart this service on first time startup, after primary Hasura applied migrations and metadata successfully.*
Client Application
Because read-only service is on different endpoint, you need to do routing on client side's GraphQL client.
The idea is simple. You just construct 2 GraphQL clients, one for mutation and one for query/subscription.
If you are using React, you may concern that it is annoyed to use 2 GraphQL clients using React hook and provider. Don't worry, Apollo client is easy customizable and composible with split:
const mutationLink = new HttpLink({
uri: 'http://localhost:8080/v1/graphql',
});
const queryLink = new HttpLink({
uri: 'http://localhost:8081/v1/graphql',
});
const subscriptionLink = new WebSocketLink({
uri: 'ws://localhost:8081/v1/graphql',
});
const link = split(
({ query }) => {
const { kind, operation } = getMainDefinition(query) as OperationDefinitionNode;
return kind === 'OperationDefinition' && operation === 'subscription';
},
subscriptionLink,
split(
({ query }) => {
const { kind, operation } = getMainDefinition(query) as OperationDefinitionNode;
return kind === 'OperationDefinition' && operation === 'mutation';
},
mutationLink,
queryLink
)
);You can explore React demo by opening http://localhost:3000 from above demo.
Conclusion
Although there are several caveats, this solution can help you improving basic performance issues. I still recommend using Hasura Cloud/Pro for easy Read Replicas and advanced Caching.
However, there isn't silver bullet for all issues. Read-only GraphQL Engine is also a cool feature that provides you new ideas for advanced system design.